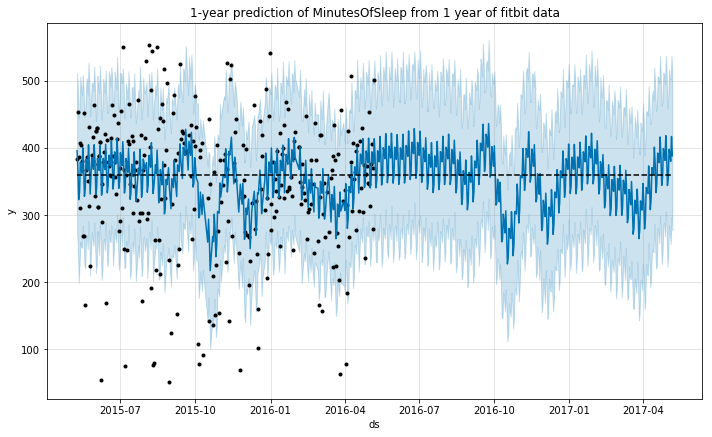
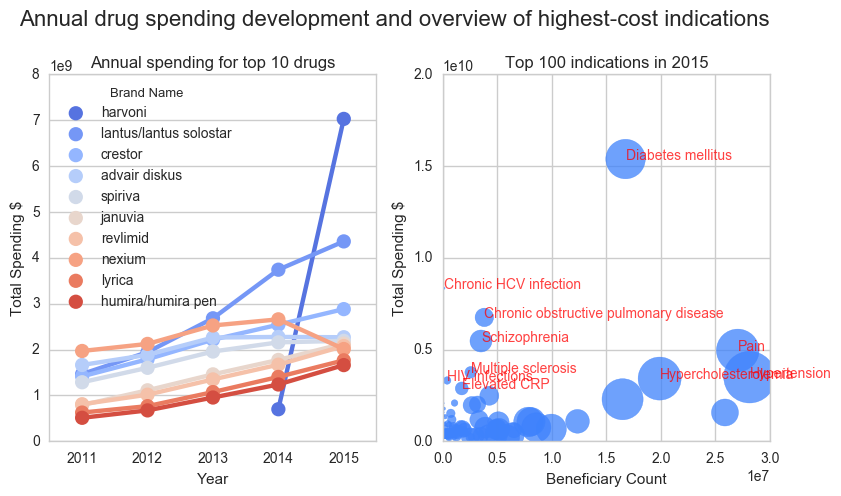
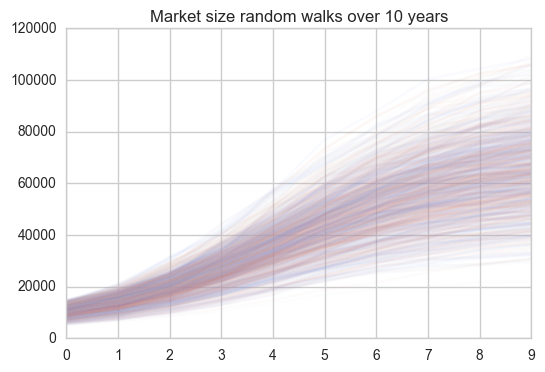
The goal of this notebook is to provide an analysis of the time-series data from a user of a fitbit tracker throughout a year. I will use this data to predict an additional year of the life of the user using Generalized Additive Models.
Data source: Activity, Sleep
Packages used:
pandas, numpy, matplotlib, seaborn Prophet import pandas as pd import numpy as np from fbprophet import Prophet import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline Data cleaning (missing data and outliers) # import the activity data activity = pd.read_csv('OneYearFitBitData.csv') # change commas to dots activity.iloc[:,1:] = activity.iloc[:,1:].applymap(lambda x: float(str(x).replace(',','.'))) # change column names to English activity.columns = ['Date', 'BurnedCalories', 'Steps', 'Distance', 'Floors', 'SedentaryMinutes', 'LightMinutes', 'ModerateMinutes', 'IntenseMinutes', 'IntenseActivityCalories'] # import the sleep data sleep = pd.read_csv('OneYearFitBitDataSleep.csv') # check the size of the dataframes activity.shape, sleep.shape # merge dataframes data = pd.merge(activity, sleep, how='outer', on='Date') # parse date into correct format data['Date'] = pd.to_datetime(data['Date'], format='%d-%m-%Y') # correct units for Calories and Steps for c in ['BurnedCalories', 'Steps', 'IntenseActivityCalories']: data[c] = data[c]*1000 Once imported, we should check for any missing data:
...